🐦 Cuckoo Filter
Problems of Bloom Filter
Bloom filters cannot remove existing items without rebuilding the entire filter
Efforts to extend Bloom filters to support deletions introduce significant space and performance overhead
Contributions of Cuckoo Filter
Cuckoo filters support adding and removing items dynamically
Cuckoo filters provide higher lookup performance
Cuckoo filters use less space than Bloom filters under many scenarios.
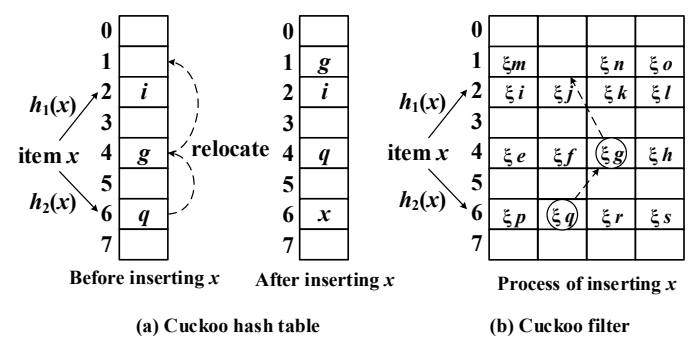
Cuckoo Hashing Basics
Components:
Two hash tables T1 and T2, each with m ...
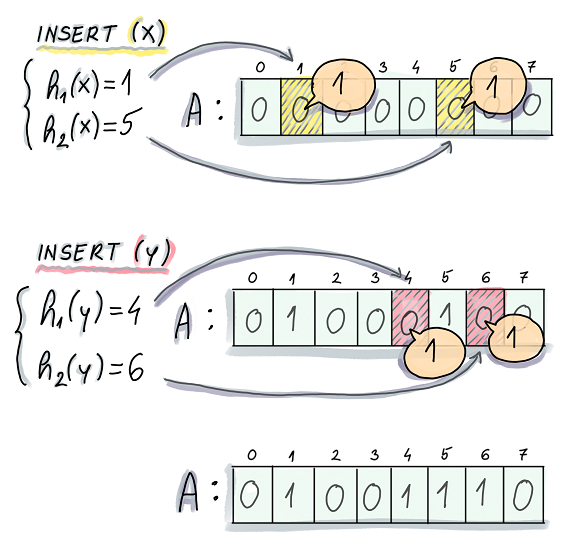
Bloom Filter
In computer science, a problem frequently occurs is determining whether an element belongs to a specific set (set membership test). A commonly used data structure is a hash table, which provides a fast and accurate search. However, a hash table could consume considerable space when there is a large amount of data.
Here comes a trade-off. If we lower our expectations for accuracy, can we achieve the goal to consume only a small space? In fact, in some scenarios, we don’t require 100% accuracy, ma ...

操作系统也是程序 (调试Firmware和Bootloader)
在OS Lab Couse 1中我们已经构建了一个最小的hello world程序
#include<sys/syscall.h>#include<unistd.h>int main() { syscall(SYS_exit, 42);}
用一种比较特殊的编译方式 (-Wl,会把后面的东西传给连接器)
$ gcc a.c -static -Wl,--entry=main
编译生成可执行文件,然后用readelf查看ELF文件, 可以看到Entry point address是0x401ce5
用objdump反汇编查看改地址对应的位置,确实是以main函数entry point
运行程序,程序依然能够正常执行
$ ./a.out; echo $?42
回到程序=状态机
是谁创建了状态机
必然是操作系统,操作系统加载了上述程序
但是操作系统也是个程序,他又由谁加载?
Bare-Metal 与程序员的约定
为了让计算机能运行任何我们的程序,一定存在一些软件/硬件的约定
CPU Reset
CPU reset后,处理器处于某个确定的状态
...
操作系统上的程序 - NJUOS
一个重新理解程序的角度 (enlightning)
程序 = 状态机 : 每个程序可以看做一个状态机
状态=M(内存) +R(寄存器)
可以用状态机和状态转移分析来分析程序的正确性
初始状态是程序启动时操作系统给安排的状态
状态转移=时钟驱动的指令执行
假设当前状态是 (M, R)
从 R[PC] 取出一条指令
解析指令,取出必要的数据
计算结果(可能具有非确定性,例如rdrand )
更新得到(M', R')
构造一个最小的hello world
失败的尝试
first try
#include<stdio.h>int main() { printf("hello world\n");}
编译hello world程序,可以看到编译出来的a.out文件是非常大的
jones@DESKTOP-60SP3JA:~/jyyos/lec2/try1$ gcc hello.cjones@DESKTOP-60SP3JA:~/jyyos/lec2/try1$ ./a.outhello worldjones@DE ...

MapReduce详解
为什么会产生MapReduce
面对大量的数据,需要充分利用大量机器的运算资源来提高效率
但是,如何利用大量机器进行并行计算,如何分配数据到各个机器上,如何处理failure,在分布式的情况下都非常复杂
而MapReduce就是用来应对这种复杂性的抽象计算模型 。这个模型可以将大型数据处理任务分解成很多单个的、可以在服务器集群中并行执行的任务,而这些任务的计算结果可以合并在一起来计算最终的结果
MapReduce主要有两个过程:Map和Reduce
Map过程
Map过程将原始数据转换成key/value pairs
以最简单的word count程序为例,这个程序的功能是计算文件中每个单词的出现次数
Map阶段, Map函数接收一个输入文件,对文件中的每一个单词输出一个键值对 (word, occurrence), 这里每个单词出现就记occurrence为1,所以这里的键值对为(word, 1)
由此,我们将一个输入文件map到了一个key/value数组
map(String key, String value): # key: document name # val ...

clflush怎么报错了
Problem
我们定义了一个数组p, 他会被初始化为0,接着我们想要将其flush回memory
因此给出如下代码
#include <stdio.h>#include <stdint.h>#ifdef _MSC_VER#include <intrin.h> /* for rdtscp and clflush */#pragma optimize("gt",on)#else#include <x86intrin.h> /* for rdtscp and clflush */#endifint p[64 * 10 + 1];int main() { for(int i = 0; i < 10; i++) _mm_clflush(&p[i * 64]);}
这段代码在电脑上可以运行,但是在gem5上会报错(clflush由CleanupSpec实现)
💡Idea
在cleanupSpec的攻击代码中,在flush array2之前,用了如下代码
for (i = 0; ...
延长分支处理时间
problem
最近在做spectre attack时,遇到了一个小问题。这是解决该问题的一种方式的小总结
我们想要延长处理分支(问号部分)的时间,以便能够speculatively execute更多分支中的语句,使得我们的实验结果看起来更显著。
if(x < ???) {}
Initial Thought: naive way
首先想到的是,在分支中放入很多需要从memory中load的数据,来延长时间,用Gem5得到的实验结果如下
time1 = __rdtscp(&junk);if(x < N[0][0] + N[1][0] + N[2][0] + N[3][0] + N[i][0] + ...) {}time2 = __rdtscp(&junk) - time1 - overhead;
N
clock cycles
N[0][0]
3
N[0][0]+N[1][0]
136
N[0][0]+N[1][0]+N[2][0]
137
N[0][0]+N[1][0]+N[2][0]+N ...
CV Couse Review
Gestalt Laws
知觉恒常性
Law of Proximity接近原则:接近/邻近的物体会被认为是一个整体
Law of Similarity相似原则: 在观察对象时容易把相似的物体分成一组
Law of Closure 闭合原则:视觉系统自动尝试将敞开的图形关闭起来,从而将其感知为完整的物体而不是分散的碎片
Law of Symmetry对称原则: 观察对象时容易将对象视为对称且围绕一个中心
Law of Continuity连续原则: 视觉倾向于感知连续的形式而不是离散的碎片
Law of Common Fate共同命运原则: 对象容易被视为行进在光滑路径上的线条
图形与背景法则:大脑将视觉区域分为主体和背景,主体包括一个场景中占据我们主要注意力的所有元素,其余则是背景
Marr视觉表示的三个阶段
Primal Sketch:处理输入的原始图像,抽取基本特征(角点、边缘、纹理、线条、边界etc.), 这些特征的集合称为基元图
2.5D Sketch:在以观测者为中心的坐标系中,由输入图像和基元图恢复场景可见部分的深度、法线方向、 ...